Construct a FCM
A feature co-occurrence matrix (FCM) records the number of co-occurrences of tokens. This is a special object in quanteda, but behaves similarly to a DFM.
require(quanteda)
require(quanteda.textplots)
require(quanteda.corpora)
corp_news <- download("data_corpus_guardian")
When a corpus is large, you have to select features of a DFM before constructing a FCM. In the example below, we first remove all stopwords and punctuation characters. Afterwards, we remove certain patterns that usually describe the publication time and date of articles. The third row keeps only terms that occur at least 100 times in the document-feature matrix.
toks_news <- tokens(corp_news, remove_punct = TRUE)
dfmat_news <- dfm(toks_news)
dfmat_news <- dfm_remove(dfmat_news, pattern = c(stopwords("en"), "*-time", "updated-*", "gmt", "bst"))
dfmat_news <- dfm_trim(dfmat_news, min_termfreq = 100)
topfeatures(dfmat_news)
## said people one new also us can
## 28412 11168 9879 8024 7901 7090 6972
## government year last
## 6821 6570 6335
nfeat(dfmat_news)
## [1] 4211
You can construct a FCM from a DFM or a tokens object using fcm(). topfeatures() returns the most frequently co-occurring words.
fcmat_news <- fcm(dfmat_news)
dim(fcmat_news)
## [1] 4211 4211
topfeatures(fcmat_news)
## trump said clinton cruz sanders one new also 2015 donald
## 2864282 2181723 2003177 1874066 1806836 1721386 1507496 1408247 1388757 1181541
You can select features of a FCM using fcm_select().
feat <- names(topfeatures(fcmat_news, 50))
fcmat_news_select <- fcm_select(fcmat_news, pattern = feat, selection = "keep")
dim(fcmat_news_select)
## [1] 50 50
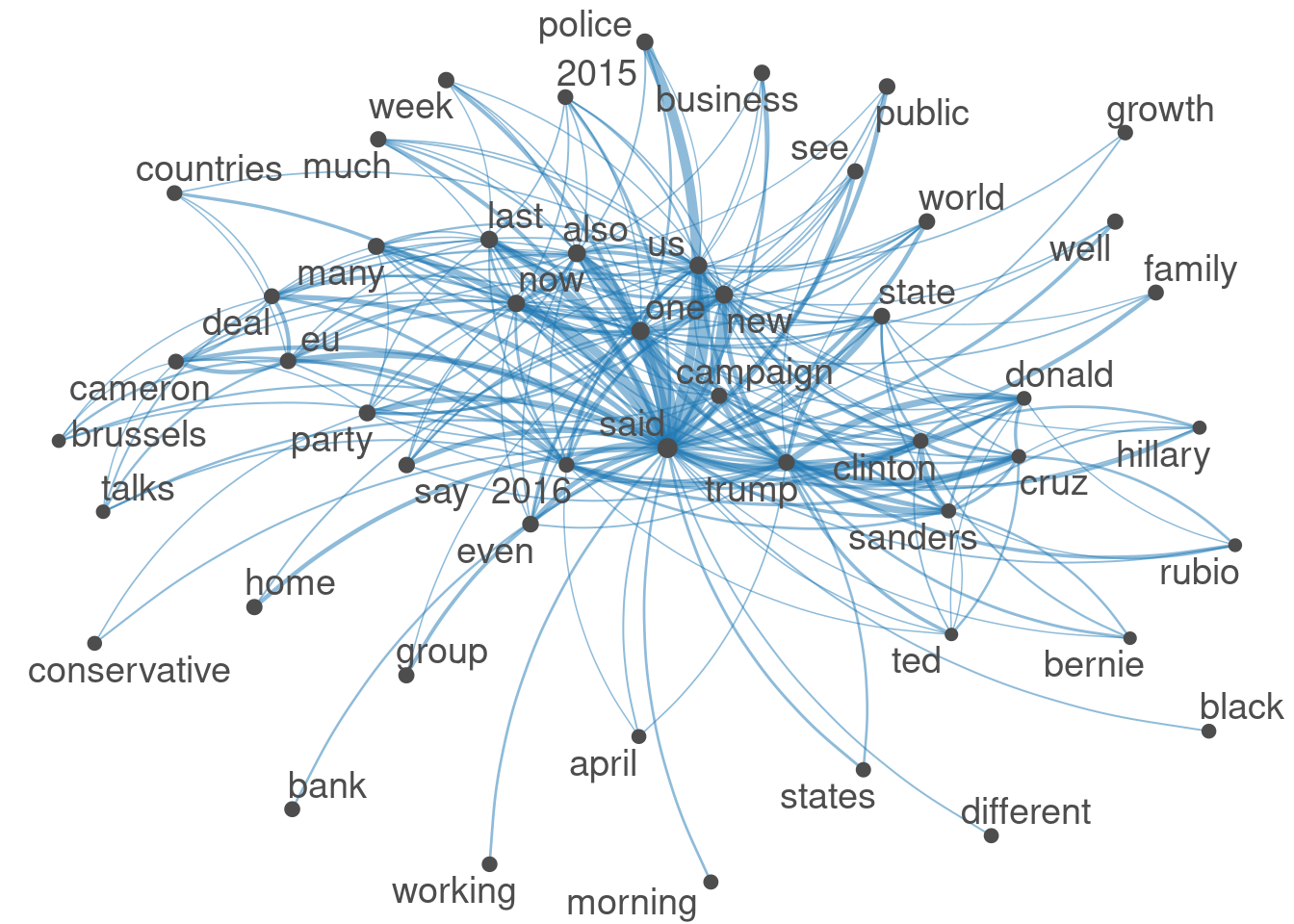
A FCM can be used to train word embedding models with the text2vec package, or to visualize a semantic network analysis with textplot_network().
size <- log(colSums(dfm_select(dfmat_news, feat, selection = "keep")))
set.seed(144)
textplot_network(fcmat_news_select, min_freq = 0.8, vertex_size = size / max(size) * 3)