Lexical diversity
require(quanteda)
require(quanteda.textstats)
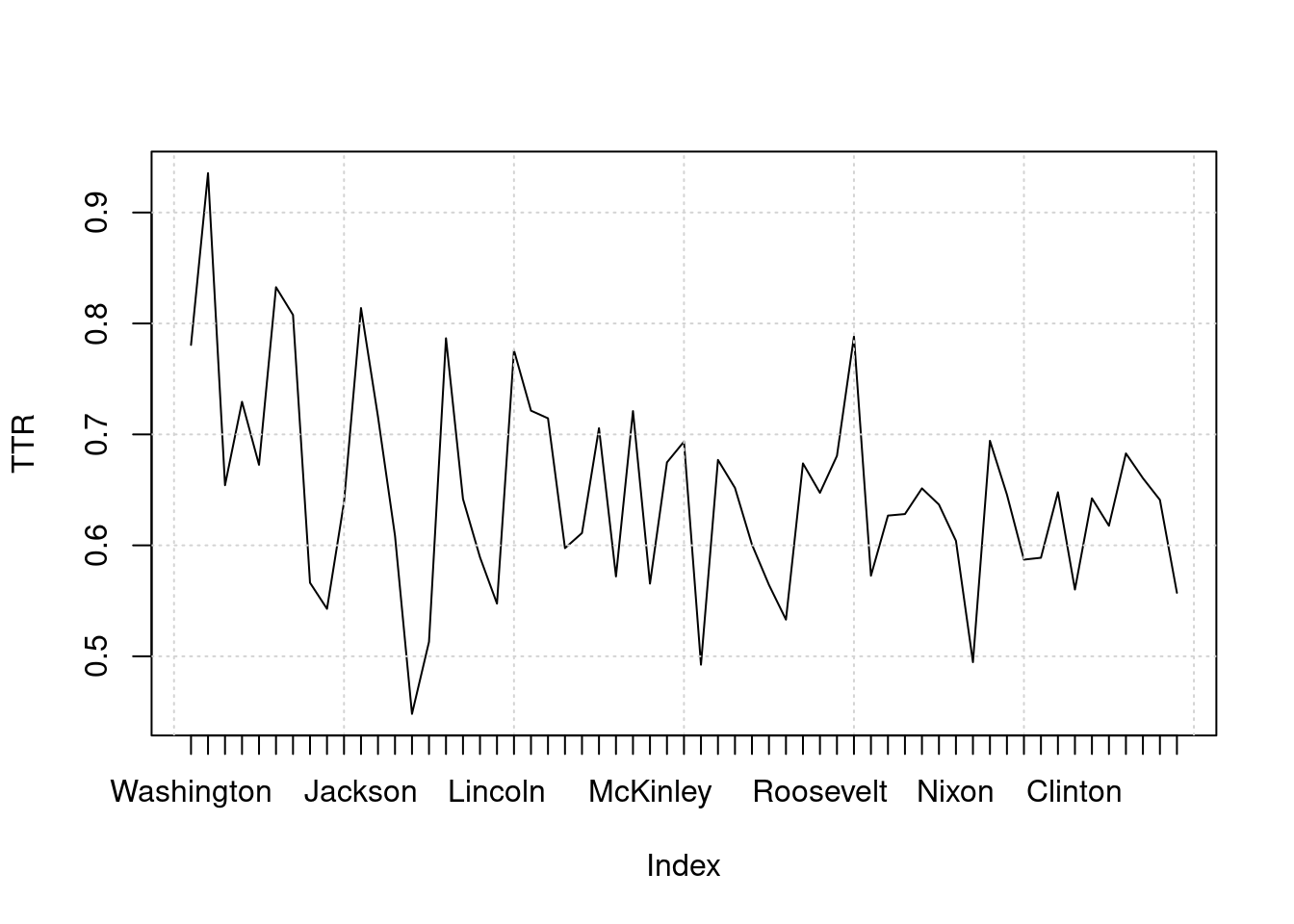
textstat_lexdiv() calculates various lexical diversity measures based on the number of unique types of tokens and the length of a document. It is useful, for instance, for analysing speakers’ or writers’ linguistic skills, or the complexity of ideas expressed in documents.
toks_inaug <- tokens(data_corpus_inaugural)
dfmat_inaug <- dfm(toks_inaug, remove = stopwords("en"))
## Warning: 'remove' is deprecated; use dfm_remove() instead
tstat_lexdiv <- textstat_lexdiv(dfmat_inaug)
tail(tstat_lexdiv, 5)
## document TTR
## 55 2005-Bush 0.6176753
## 56 2009-Obama 0.6828645
## 57 2013-Obama 0.6605238
## 58 2017-Trump 0.6409537
## 59 2021-Biden 0.5572316
plot(tstat_lexdiv$TTR, type = "l", xaxt = "n", xlab = NULL, ylab = "TTR")
grid()
axis(1, at = seq_len(nrow(tstat_lexdiv)), labels = dfmat_inaug$President)