Relative frequency analysis (keyness)
Keyness is a signed two-by-two association score originally implemented in WordSmith to identify frequent words in documents in a target and reference group.
require(quanteda)
require(quanteda.textstats)
require(quanteda.textplots)
require(quanteda.corpora)
require(lubridate)
corp_news <- download("data_corpus_guardian")
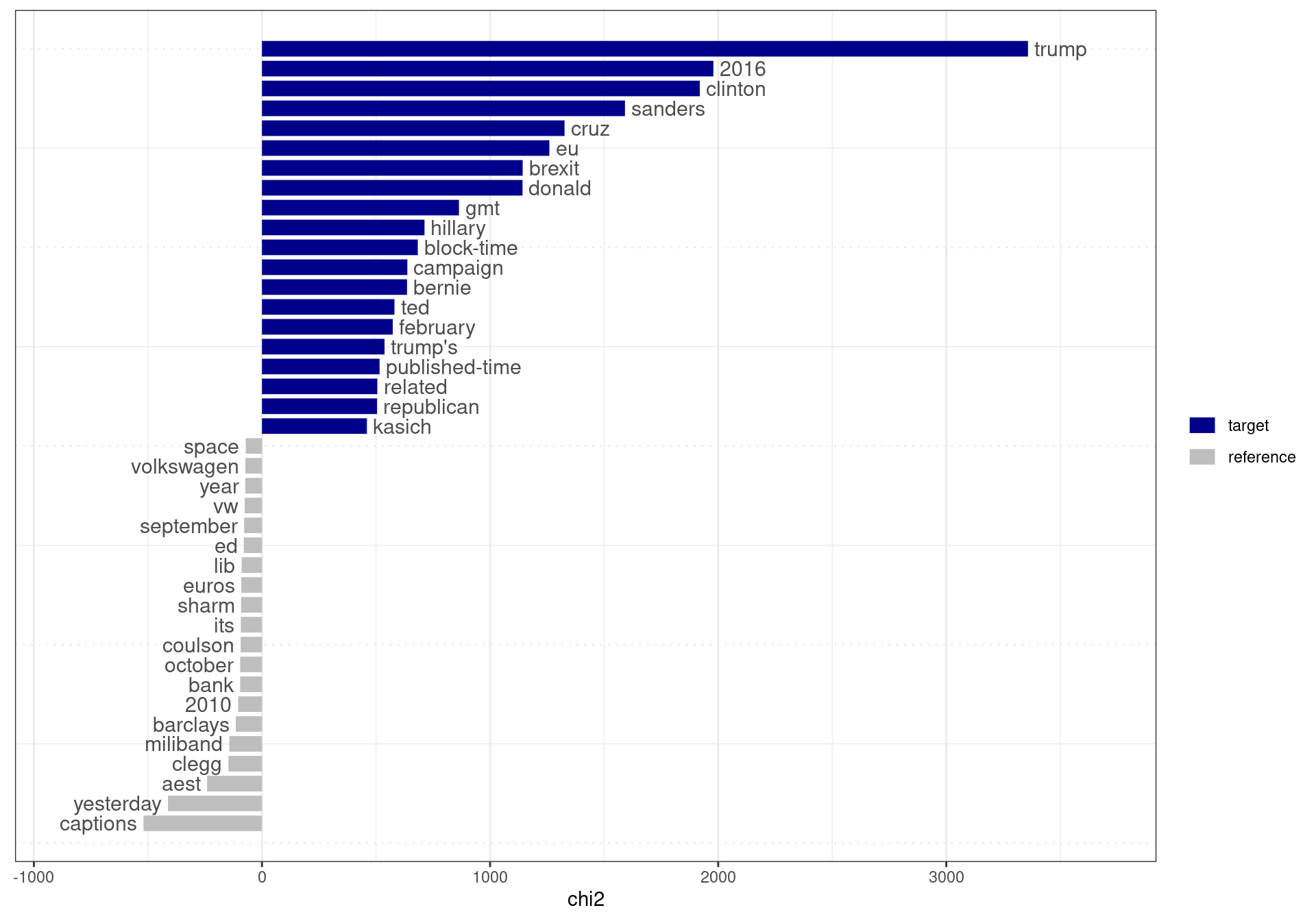
Using textstat_keyness(), you can compare frequencies of words between target and reference documents. In this example, target documents are news articles published in 2016 and reference documents are those published in 2012-2015. We use the lubridate package to retrieve the year of the publication of an article.
toks_news <- tokens(corp_news, remove_punct = TRUE)
dfmat_news <- dfm(toks_news)
tstat_key <- textstat_keyness(dfmat_news,
target = year(dfmat_news$date) >= 2016)
textplot_keyness(tstat_key)